

Description
Introduction
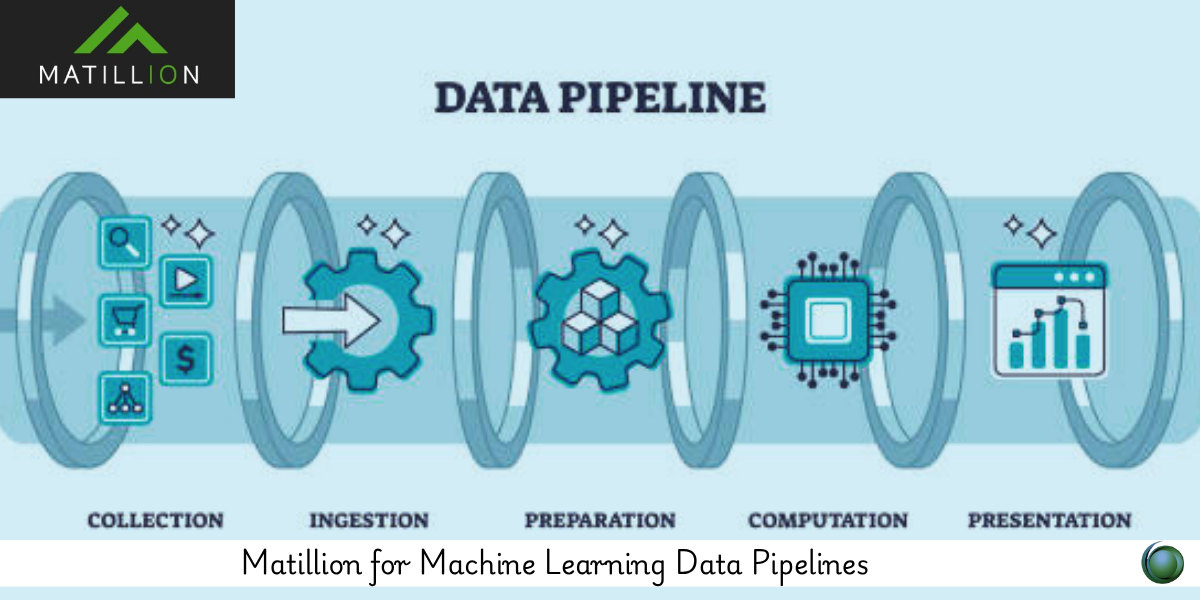
Machine learning (ML) success depends on clean, reliable, and scalable data pipelines. This course teaches how to leverage Matillion ETL to prepare, transform, and orchestrate data workflows tailored for ML projects. From ingesting raw data to engineering features and exporting model-ready datasets, you’ll learn how Matillion fits seamlessly into a modern ML pipeline architecture.
Prerequisites
-
Basic knowledge of machine learning concepts
-
Familiarity with Matillion ETL and its interface
-
Experience with cloud data warehouses (Snowflake, Redshift, BigQuery)
-
Understanding of Python or ML frameworks is helpful (optional)
Table of Contents
1. Introduction to ML Data Pipelines
1.1 The Role of ETL in ML Workflows
1.2 Overview of Pipeline Stages
1.3 Benefits of Using Matillion for ML Data Prep
2. Ingesting Raw Data for ML
2.1 Connecting to APIs, Files, and Databases
2.2 Handling Unstructured and Semi-Structured Data
2.3 Automating Data Ingestion at Scale
3. Data Cleaning and Transformation
3.1 Removing Duplicates, Nulls, and Noise
3.2 Data Normalization and Standardization
3.3 Creating Consistent Label Formats
4. Feature Engineering with Matillion
4.1 Generating New Variables and Indicators
4.2 Aggregations, Joins, and Time-Series Features
4.3 Exporting Feature Sets for Training
5. Integration with Python and ML Tools
5.1 Writing Python Scripts in Matillion
5.2 Passing Data to Jupyter, SageMaker, or Vertex AI
5.3 Orchestrating Model Training Workflows
6. Data Versioning and Reproducibility
6.1 Managing Data Snapshots
6.2 ETL Version Control Best Practices
6.3 Logging and Metadata for ML Traceability
7. Orchestration and Scheduling for ML Pipelines
7.1 Triggering ETL with Model Events
7.2 Scheduling Retraining and Data Updates
7.3 Building End-to-End ML Lifecycle Pipelines
8. Exporting and Delivering Model-Ready Data
8.1 Exporting to Cloud Storage or ML Platforms
8.2 Managing Real-Time vs Batch Data Feeds
8.3 Feeding Data into MLOps Pipelines
9. Monitoring and Optimization
9.1 Tracking ETL Job Performance
9.2 Detecting Pipeline Bottlenecks
9.3 Improving Data Pipeline Efficiency for ML
10. Case Study: End-to-End ML Data Pipeline in Matillion
10.1 Use Case Overview
10.2 Step-by-Step Pipeline Walkthrough
10.3 Lessons Learned and Best Practices
Matillion enables machine learning teams to build robust, scalable, and automated data pipelines with minimal coding. By combining visual workflows, Python integration, and cloud-native scalability, it empowers data engineers and scientists to collaborate efficiently and accelerate ML delive


Reviews
There are no reviews yet.