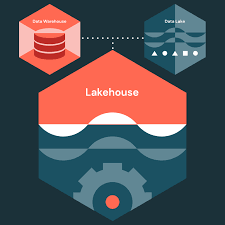
Databricks for Data Lakes and Lakehouse focuses on building modern data architectures that combine the scalability of data lakes with the performance and reliability of data warehouses. Databricks uses Apache Spark and Delta Lake to support unified data processing, analytics, and machine learning workflows. This training explains how lakehouse architecture enables centralized storage for structured and unstructured data while maintaining ACID transactions and schema management. It also covers data ingestion, transformation, governance, and real-time analytics within Databricks environments. You will learn how to design scalable and efficient lakehouse solutions for enterprise data platforms. The course also highlights best practices for performance optimization, collaboration, and secure data management in cloud ecosystems.
Showing the single result