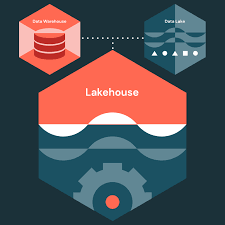
Data Lakes with Databricks focus on storing, processing, and analyzing large volumes of structured and unstructured data using the Databricks platform. Databricks combines Apache Spark with cloud-based infrastructure to support scalable and high-performance data lake architectures. This training explains how data lakes centralize data from multiple sources for analytics, machine learning, and business intelligence workflows. It also covers Delta Lake features such as ACID transactions, schema enforcement, and version control for reliable data management. You will learn how to build and manage scalable data lake solutions that support real-time and batch processing. The course also highlights best practices for data governance, optimization, and cloud-based analytics environments.
Showing the single result