

Description
Introduction
Big data analytics has become essential in the modern data-driven world, enabling businesses to extract valuable insights from vast amounts of structured and unstructured data. Apache Hadoop, with its Hadoop Distributed File System (HDFS) and Hive, plays a significant role in managing and processing big data efficiently. HDFS provides a scalable and fault-tolerant platform for storing data, while Hive enables users to query and analyze the data in a familiar SQL-like syntax. This guide covers how to use Apache Hadoop and Hive for big data processing, enabling organizations to handle, store, and query large datasets effectively.
Prerequisites
- Basic understanding of Big Data concepts.
- Familiarity with distributed computing and parallel processing.
- Prior knowledge of databases and SQL will be helpful but not required.
- Experience with basic programming concepts, particularly in Java or Python.
Table of Contents
1. Introduction to Big Data and Hadoop Ecosystem
1.1 What is Big Data?
1.2 Overview of Apache Hadoop
1.3 Components of the Hadoop Ecosystem
2. The Hadoop Distributed File System (HDFS)
2.1 Understanding the Architecture of HDFS
2.2 Setting Up HDFS for Big Data Storage
2.3 Working with HDFS Commands: File Management and Operations
2.4 Ensuring Data Availability and Fault Tolerance with HDFS
3. Introduction to Apache Hive
3.1 What is Apache Hive?
3.2 Hive Architecture and Components
3.3 Installing and Configuring Hive in Hadoop
4. Using Hive for Data Querying and Analysis
4.1 Basics of HiveQL (Hive Query Language)
4.2 Creating Tables and Databases in Hive
4.3 Loading Data into Hive Tables from HDFS
4.4 Writing SQL-like Queries in Hive for Data Analysis
5. Advanced Hive Features
5.1 Partitioning and Bucketing in Hive for Efficient Data Management
5.2 Using Hive for Complex Data Types (Arrays, Maps, Structs)
5.3 Performance Optimization in Hive: Indexing and Caching
5.4 Hive Joins, Subqueries, and Grouping for Advanced Analytics
6. Data Storage and Management with HDFS and Hive
6.1 Managing Large Datasets with HDFS
6.2 Data Compression and File Formats in HDFS
6.3 Efficient Data Management and Access in Hive
7. Integrating Hadoop with Other Big Data Tools
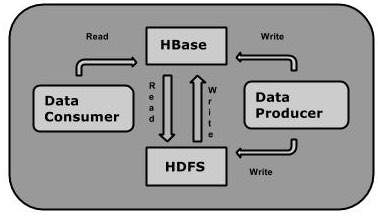
7.1 Integrating Apache HBase for Real-Time Data Access
7.2 Using Apache Spark with Hive for In-Memory Processing
7.3 Connecting Hive with Apache Pig and Flume for ETL Processes
8. Security and Governance in Hadoop and Hive
8.1 Implementing Security in HDFS with Kerberos Authentication
8.2 Data Encryption and Access Control in Hive
8.3 Managing Data Governance in Hadoop Ecosystem
9. Troubleshooting and Performance Tuning
9.1 Diagnosing Common Issues in HDFS and Hive
9.2 Performance Tuning for HDFS: Block Size, Replication, and Caching
9.3 Optimizing Hive Query Performance: Partitioning, Bucketing, and Execution Plans
10. Best Practices for Big Data with HDFS and Hive
10.1 Organizing and Structuring Data for Efficient Querying
10.2 Optimizing HDFS for Scalability and Fault Tolerance
10.3 Using Hive for Complex Analytics at Scale
Conclusion
Apache Hadoop with HDFS and Hive offers a powerful combination for managing, storing, and analyzing big data. HDFS provides a scalable and fault-tolerant storage solution, while Hive enables easy querying of large datasets using SQL-like syntax. By mastering HDFS and Hive, organizations can effectively manage vast amounts of unstructured and structured data, optimizing storage and query performance. Implementing best practices for data management, security, and performance tuning ensures that big data environments run efficiently and securely, enabling businesses to extract valuable insights and drive data-driven decisions.







Reviews
There are no reviews yet.